Der Akzeptor Der erkennende Automat
Eine Präsentation von Philipp Hauer vom 11.01.2008. Erstmals gehalten am Richard-Wossidlo-Gymnasium am 09.01.2008. ©
Inhalt
- Einleitung
- Aufbau des Akzeptors
- Vergleich mit Transduktor
- Arbeitsweise
- Sprache des Akzeptors
- Fazit
- Beispiele und Übungen:
- Die Powerpoint-Präsentation
- Quellen
Einleitung
Der Akzeptor, auch der erkennende Automat oder endlicher Automat ohne Ausgabe genannt, ist ein essenzieller Bestandteil der Theoretischen Informatik. Mit ihm beginnen wir, mit Sprachen und Grammatiken umzugehen.
Aufbau des Akzeptors
Der Akzeptor ist ein 5-Tupel mit A = (X, Z, f, z0, ZE), der ohne die Ausgabefunktion g und das Ausgabewort Y auskommt. Dafür besitzt er eine Menge von Endzuständen ZE.
| Variable | Bedeutung | Bedingung |
|---|---|---|
| X | Eingabealphabet | nichtleere, endliche Menge |
| Z | Zustandsmenge | nichtleere, endliche Menge |
| f | überführungsfunktion | f: X x Z --> Z
= Überführungsfunktion, die jedem Paar (Eingabezeichen X, Zustand Z) einem Folgezustand Z zuordnet |
| z0 | Anfangszustand | z0 ∈ Z |
| ZE | Endzustandsmenge | ZE ⊆ Z |
Exkurs Teilmenge ⊂/⊆:
Was bedeutet das eigentlich genau: ⊆? Dazu folgende Illustrationen:
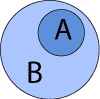 |
Die echte Teilmenge:
A ⊂ B, wenn A < B |
 |
Die Teilmenge:
A ⊆ B, wenn A ≤ B |
| Gegeben sind die 2 Mengen A und B.
1) A enthält dabei Elemente von B, ist aber nicht identisch B. Somit kann man schreiben: A ist eine echte Teilmenge von B. 2) Kann A aber auch alle Elemente von B annehmen, so schreiben wir nur: A ist eine Teilmenge von B. |
|||
Vergleich mit dem Transduktor
Im folgendem wollen wir den Akzeptor mit dem Transduktor, dem Automaten mit Ausgabe, vergleichen.
| Variable | Bedeutung | Bedingung |
|---|---|---|
| X | Eingabealphabet | nichtleere, endliche Menge |
| Y | Ausgabealphabet | nichtleere, endliche Menge |
| Z | Zustandsmenge | nichtleere, endliche Menge |
| f | überführungsfunktion | f: X x Z --> Z
= Überführungsfunktion, die jedem Paar (Eingabezeichen X, Zustand Z) einem Folgezustand Z zuordnet |
| g | Ausgabefunktion | g: X x Z --> Y*
= Ausgabefunktion, die jedem Paar (Eingabezeichen X, Zustand Z) ein Ausgabewort Y zuordnet |
| z0 | Anfangszustand | z0 ∈ Z |
Wir sehen also bestätigt, was wir schon wussten: Der Transduktor hat ein Ausgabealphabet Y und eine Ausgabefunktion g, jedoch keine Endzustandsmenge ZE.
Veranschaulichen wir uns nun die Arbeitsweise des Transduktors:
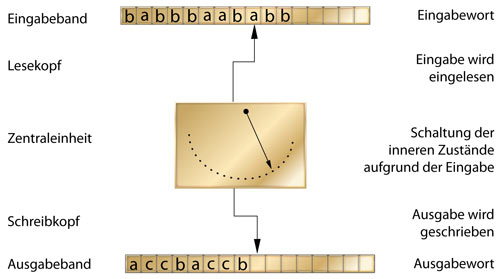
Nach [1].

Das Eingabewort auf dem Eingabeband wird durch den Lesekopf zeichenweise eingelesen. In der Zentraleinheit werden aufgrund dieser Eingabe und des jeweils momentanen Zustandes sowohl der Folgezustand geschaltet, als auch eine Ausgabe auf das Ausgabeband geschrieben.
Arbeitsweise des Akzeptors
Analog dazu können wir die Arbeitsweise des Akzeptors illustrieren:
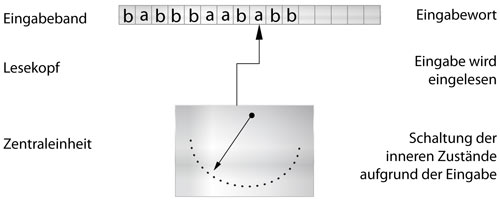
Nach [1].

Wie beim Transduktor wird hier das Eingabewort eingelesen, und entsprechend diesem die Zustände geschaltet. Jedoch wechselt der Akzeptor durch Eingabezeichen und Überführungsfunktion ausgehend vom momentanen Zustand in einen anderen Zustand (oder verbleibt im aktuellen). Jetzt stellt sich die Frage: Welchen Sinn hat ein Automat der keine Ausgabe besitzt? ...
Ist der Akzeptor nach Abarbeiten des Eingabewortes im definierten Endzustand, dann ist das Eingabewort akzeptiert; andernfalls ist es nicht akzeptiert Das ist ein sehr wichtiger Fakt beim Arbeiten mit dem erkennenden Automaten: Der Akzeptor akzeptiert das Eingabewort, wenn das letzte Eingabezeichen zum einem Endzustand führt. Die Menge aller akzeptierten Eingabeworte bezeichnet man als die Sprache des Automaten L(A); L steht für Language (dt: Sprache) und A für Automat.
Sprache des Akzeptors
Die Sprache L(A) eines Akzeptors lässt sich mit folgender Formel definieren:
L(A) := {w|w ∈ X* und f*(w; z0) ∈ ZE}
Zum besseren Verständnis kann man die Definition in L(A) := {Allgemeine Form|Bedingungen} ausdrücken.
Dabei ist w das Eingabewort, das ein Element des Eingabewortalphabetes X* sein muss. X* umfasst dabei alle möglichen Worte, die aus Zeichen des Eingabealphabetes X entstehen können, sowie das leere Wort ε. Um die zweite Bedingung verstehen zu können, erinnern wir uns an den Aufbau des Akzeptors:
| Variable | Bedeutung | Bedingung |
|---|---|---|
| f | Überführungsfunktion | f: X x Z --> Z
= Überführungsfunktion, die jedem Paar (Eingabezeichen X, Zustand Z) einem Folgezustand Z zuordnet |
f : X x Z --> Z
f*: X* x Z --> Z
f*(w;z0)
Die Form f*(w; z0) kann man sich folgendermaßen erklären: Das Eingabewort w muss ein Element der Eingabewortmenge X* und der Startzustand z0 ist ein Element der Zustandsmenge Z, dazu noch jenes, in dem der Automat beginnt.
Somit wird dem Automaten alles in die Hand gegeben, was er benötigt: Ein Eingabewort, sowie ein Startzustand. Davon ausgehend kann er mittels seiner Überführungsfunktionen, schließlich in einen bestimmten Zustand gelangen. Dieser Zustand muss ein Element der Zustandsmenge ZE sein. f* ist folglich eine "Folge von Überführungsfunktionen, die beginnend im Startzustand z0 mit dem Eingabewort w den Automaten in einen Endzustand ZE Überführen" [2]. Die Funktion f*(w; z0) führt den Automaten also nach Abarbeiten des Eingabewortes w in einen Zustand, der ein Element der Endzustandsmenge ZE sein muss.
Sind beide Bedingungen erfüllt, so ist das Wort w ein Satz der Sprache des Akzeptors L(A).
Fazit
Somit erkennen wir, dass Akzeptoren die syntaktische Korrektheit einer Eingabekette (Zeichenkette/string) testen bzw. prüfen, ob sie ein Satz der Sprache des Automaten ist. Sie kennen nur true (akzeptiert) oder false (nicht akzeptiert).
Beispiele und Übungen
Mit der Theorie im Hinterkopf ist es nun ein Leichtes, den erkennenden Automaten in Anwendung zu verstehen.
Bei der Darstellung und der Simulation von Automaten brilliert das Automatenprogramm AutoEdit (Eine Komponente des Softwarepakets AtoCC, Freeware). Alle folgenden Graphen wurden damit erstellt und getestet. Daher biete alle *.xml-Dateien zu jedem Beispiel an, mit der man den jeweiligen Automaten in AutoEdit öffnen, testen und ändern kann: Hier gehts zu den Automatendateien für AutoEdit.
Um einen Akzeptor in AutoEdit zu integrieren, müssen 2 Dinge beachtet werden:
- Als Automatentyp DEA wählen, was jedoch standardmäßig der Fall ist.
- Um einen Zustand die Eigenschaft Endzustand zuzuweisen, muss bei dessen Eigenschaften das Attribut "FinalState" auf "YES" gestellt werden.
Exkurs DEA:
Die Abkürzung DEA steht für "Deterministischer Endlicher Automat".
Ein Automat ist endlich, wenn die Anzahl seiner Zustände endlich ist. Deterministisch ist ein Automat, wenn er unter Eingabe eines Zeichens einen eindeutig bestimmten Folgezustand annimmt.
Beispiel 1: Der Vierertester
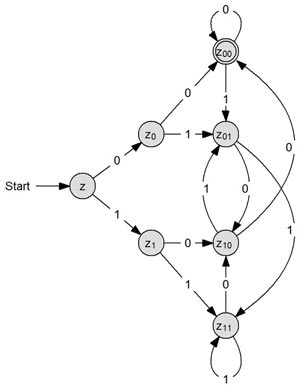
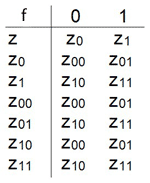
Der Vierertester prüft, ob eine Dualzahl durch 4 teilbar ist, d. h. ob die beiden letzten Zahlen Nullen sind. So sind die Binärzahlen 110100 und 100 durch 4 teilbar, jedoch 1101 und 0010011 nicht. Wir benötigen also ein Eingabealphabet mit den Zeichen 1 und 0, sowie eine Reihe von Zuständen, in welche wir einen Startzustand und einen Endzustand definieren. Formal wäre das:
- X = {0, 1}
- Z = {z, z0, z1, z00, z01, z10, z11}
- z0 = {z}
- ZE = {z00}
Dabei bedeutet z1, dass der Automat bis jetzt eine Zahl gelesen hat und zwar die 1. Analog meint z01, dass mindestens zwei Zahlen gelesen wurden und zwar zuletzt 0 und 1. Demnach ist klar, dass das letzte Eingabezeichen in den Zustand z00, unserem Endzustand, führen muss.
Beispiel 2: Der Syntaxprüfer
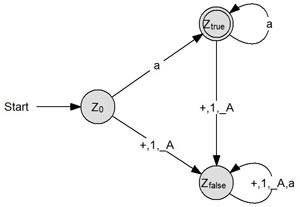
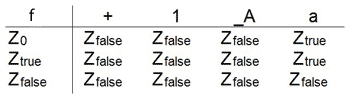
Hinweis: Der Unterstrich vor dem großem A rührt daher, dass AutoEdit keine nicht escapten (_) Großbuchstaben akzeptiert.
Der Syntaxprüfer, überprüft, ob das Eingabewort bestimmten Bedingungen genügt. In unserem Beispiel nehmen wir an, dass nur Kleinbuchstaben akzeptiert werden, jedoch keine Großbuchstaben, Ziffern oder Sonderzeichen (z. B. für die Eingabe eines Benutzernames).
Zur Realisierung wählen wir ein exemplarisches Eingabealphabet:
- X = {a, A, 1, +} (Auswahl)
- Z = {z0, ztrue, zfalse}
- ZE = {ztrue}
Solange erlaubte Zeichen (Kleinbuchstaben) benutzt werden, verbleibt der Automat im Endzustand ztrue. Sollte auch nur einmal ein unerlaubtes Zeichen kommen, geht der Akzeptor in den Zustand zfalse und verbleibt dort, auch wenn wieder ein erlaubtes Zeichen eingegeben wird. Z. B.:
"a1+" und "A1a" werden nicht akzeptiert.
"a" und "aaa" werden akzeptiert.
Arbeiten mit der Sprachdefinition L(A) am Beispiel der Phrasentester
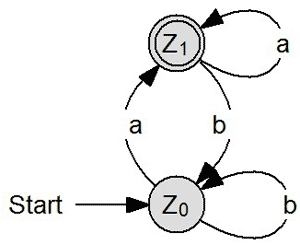
Nun wollen wir zum einen das Lesen von Graphen wiederholen, aber auch die Anwendung der Definition von L(A) am konkreten Beispiel einmal näher betrachten. Die Fragen, die wir uns zu jedem ist Graphen stellen, ist folgende: Welche Eingabeworte werden von den jeweiligen Akzeptoren akzeptiert bzw. welchen Bedingungen muss das Eingabewort genügen, um akzeptiert zu werden. Davon ausgehen können wir L(A) definieren.
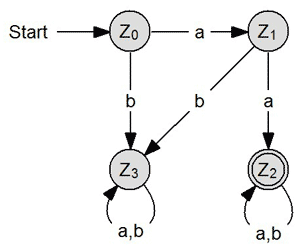
X = {a, b}
|
|
Akzeptiert werden alle Worte, die mit dem Zeichen "a" enden ("*a"). L(A) = {wna| w ∈ X* und n ∈ N} Alle akzeptierten Eingabeworte müssen die Form wna ausweisen, wobei w ein Element des Eingabealphabetes X* sein muss und n ein Element der natürlichen Zahlen (0, 1, 2, 3, 4...) sein muss. wn beschreibt damit eine Zeichenkette beliebiger Länge aus den Zeichen a und b. |
|
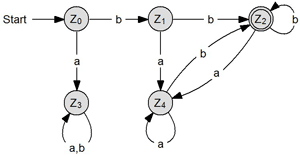
L(A) = {aawn| w ∈ X* und n ∈ N} |
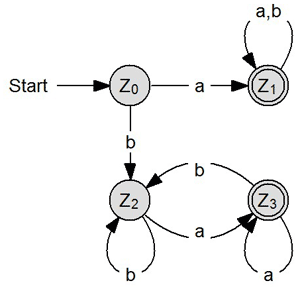
L(A) = {bwnb| w ∈ X* und n ∈ N} |
|
Zum ersten Mal haben wir es hier mit einer wirklichen EndzustandsMENGE zu tun: Es gibt 2 mögliche Endzustände, was sich natürlich auch auf die Sprachdefinition auswirkt: L(A) = {awn oder wna| w ∈ X* und n ∈ N} |
Hier muss die Anzahl der Zeichen "a" und der Zeichen "b" gerade sein. L(A) = {w|w ∈ X*, w enthält gerade Anzahl von a und b} oder mathematisch L(A) = {w|w ∈ X*, an ⊆ w, n/2 ∈ N, bm ⊆ w, m/2 ∈ N} Die Anzahl des Zeichens a ist eine Teilmenge des Eingabewortes w, wobei n die Anzahl beziffert. Diese muss geteilt durch 2 eine natürliche Zahl ergeben. Ist dies der Fall, so handelt es sich um eine gerade Zahl. |
Beispiel 3: Der Morse-SOS-Melder
Gesucht ist ein Morse-Melder für den Notruf SOS. Seine Eingabezeichen seien die Morsezeichen . und _, sowie das Trennzeichen /. Der Akzeptor soll alle Eingaben akzeptieren, die die Folge
Trennzeichen SOS Trennzeichen
/..._ _ _.../
enthalten.
Eine mögliche Lösung wäre:
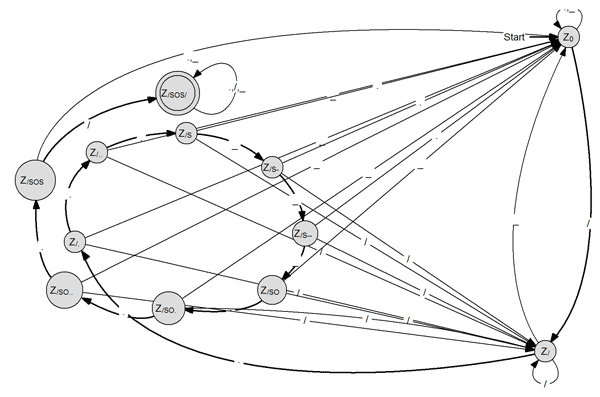
Die fett hervorgehobenen Pfeile bilden die "Ideallinie". Ist sie durchgelaufen, wurde SOS gesendet. Sollte aber während dieser Linie ein unerlaubtes Zeichen auftreten, dann springt er aus dieser heraus.
Hier haben wir das Prinzip des Vierertesters weitergetrieben. Mit Hilfe der Zustände kann sich der Automat "merken", welche Zeichen bereits eingeben wurden und er weiß daher, wann der Notruf vollständig ist.
Die Powerpoint-Präsentation
Diesen Artikel gibt es auch als Powerpoint-Präsentation. Diese bietet Animationen und Unterstützung bei einem Vortrag. Hier geht es zum Download: Der Akzeptor (ppt; 1,61 MB).
Quellen
- [1]: Friedrich Gasper, Ina Leiß, Mario Spengler, Hermann Stimm: "Technische und theoretische Informatik". 1. Auflage. Bayerischer Schulbuch-Verlag München (1992)
- [2]: Tino Hempel: "Akzeptoren - Endliche Automaten ohne Ausgabe". URL: http://www.tinohempel.de/info/info/ti/akzeptor.htm [Stand: 11.01.08].
Die Akzeptorbeispiele sind aus Quelle [1] entliehen und ggf. modifiziert.